Learning-to-rank with LightGBM (Code example in python)
LightGBM is a framework developed by Microsoft that that uses tree based learning algorithms. One of the cool things about LightGBM is that it can do regression, classification and ranking (unlike other frameworks, LightGBM has some functions created specially for learning-to-rank)
What is learning-to-rank and how it’s different from our classical regression and classification problems?
I used to think that with regression and classification I could solve (or at least try to solve) every problem I’d ran up to. And actually I was kind-of right.
Ranking is a natural problem because in most scenarios we have tons of data and limited space (or time). Do you imagine having to go through every single webpage to find what you’re looking for? Me neither, because we rely on search-engines. What a search engine is doing is to provide us with a ranking of the webpages that match (in a sense or another) our query.

Of course, for this purpose, one can use some classification or regression techniques. For instances, I could label some documents (or web-pages, or items, or whatever we’re trying to rank) as relevant and others as not-relevant and treat ranking as a classification problem. But that’s not really what we want to do: okay, we may want to know which items are relevant, but what we really want is to know how relevant is an item. Oh, so we can treat this as a regression problem? Actually we can: if we obtain some feedback on items (e.g: five-star ratings on movies) we can try to predict it and make an order based on my regression model prediction. That seems like a good approach and actually a lot of people use regression tasks to provide a ranking (which is totally fine), but again, predicting a rating is not quite what we want to do.

So, as regression and classification are specific task and they have specific metrics that have little to nothing to do wth ranking, some new species of algorithms have emerged: learning-to-rank (LTR) algorithms. LTR algorithms are trained to produce a good ranking
What is a Gradient Boosting Machine?
A Gradient Boosting Machine (GBM) is an ensemble model of decision trees, which are trained in sequence . In each iteration, the algorithm learns the decision trees by looking at the residuals errors.

What’s new in the LightGBM framework is the way the trees grow: while on traditional framework trees grow per level, here the grow is focused on the leafs (you know, like Bread-First Search and Deep-First Search).
If you want to know more about the implementation of LightGBM and its time and space complexity, you should check out this paper: https://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
How does GBM rank?
Now if you’re familiar with trees then you know how this guys can do classification and regression and they’re actually pretty good at it but now we want to rank so… how do we do it?

In order to do ranking, we can use LambdaRank as objective function. LambdaRank has proved to be very effective on optimizing ranking functions such as nDCG. If you want to know more about LambdaRank, go to this article: https://www.microsoft.com/en-us/research/publication/from-ranknet-to-lambdarank-to-lambdamart-an-overview/
Also, to evaluate the ranking our model is giving we can use nDCG@k (this one comes by default when we use LGBMRanker). Normalized discounted cummulative gain (nDCG) is a very popular ranking metric and it measures the gain of a document regarding in what’s it’s position: a relevant document placed within the first positions (at the top) will have a greater gain than a relevant document placed at the bottom.
Example (with code)
I’m going to show you how to learn-to-rank using LightGBM:
import lightgbm as lgb
gbm = lgb.LGBMRanker()Now, for the data, we only need some order (it can be a partial order) on how relevant is each item. A 0–1 indicator is good, also is a 1–5 ordering where a larger number means a more relevant item. I’ll say this again: with a partial order we’re ok!
Now we need to prepare the data for train, validation and test. For this purpose I’ll use sklearn:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, random_state=1)
Now let’s suppose that you only have one query: this means that you want to create order over all of your data. If you have more data or, for some reason, you have different train groups then you’ll have to specify the size of each group in q_train, q_test and q_val (check the documentation of LightGBM for details: https://github.com/microsoft/LightGBM)
query_train = [X_train.shape[0]]
query_val = [X_val.shape[0]]
query_test = [X_test.shape[0]]Now it’s time to train our model:
gbm.fit(X_train, y_train, group=query_train,
eval_set=[(X_val, y_val)], eval_group=[query_val],
eval_at=[5, 10, 20], early_stopping_rounds=50)The training output will look like this:
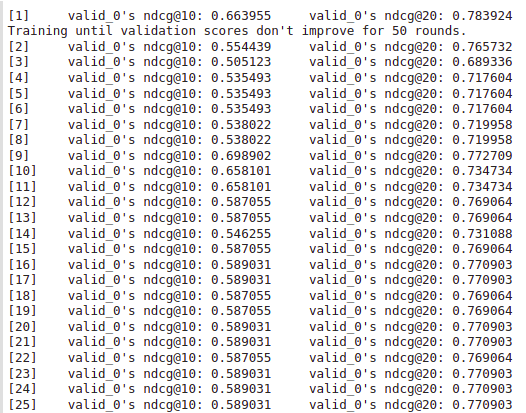
Now let’s break this code into parts:
- X_train, y_train, q_train : This is the data and the labels of the training set and the size of this group (as I only have one group, it’s size is the size of the entire data)
- X_val, y_val, q_val: Same but with the validation set.
- eval_at : This parameters are the k I’ll use to evaluate nDCG@k over the validation set
- early_stopping_rounds : Parameter for early stopping so your model doesn’t overfit
There are some more hyper-parameters you can tune (e.g: the learning rate) but I’ll leave that for you to play with.
Finally we want to know how good (or bad) is our ranking model, so we make predictions over the test set:
test_pred = gbm.predict(X_test)The output will be something like this:
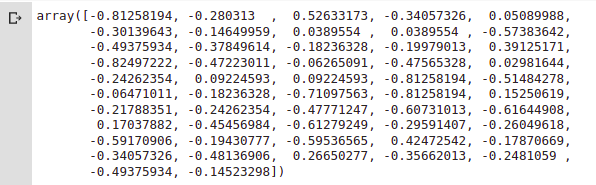
Now what the $#%& are this numbers and what do they mean? This numbers can be interpreted as probabilities of a item being relevant (or being at the top), so in order to produce our ranking we need only to order the set on this numbers. If you’re using pandas it will be something like this:
X_test["predicted_ranking"] = test_predX_test.sort_values("predicted_ranking", ascending=False)
And finally we can evaluate these results using our favorite ranking metric (Precision@k, MAP@K, nDCG@K).
Well, for now that’s it :)
